Learn about how we can define a linear model to make predictions about one variable (the DV) from another (the IV)
You’ll then learn about R2 (read : “R-squared”) - professor’s favorite statistic - and how this quantifies the amount of error in a model.
Learn how our good friend the z-score can be used to calculate a correlation coefficient. Wow!
Part 1 : Making Predictions with Models
At the beginning of the semester, we talked about how the goal of psychological science is to make predictions about people, while recognizing that our predictions will not perfectly match what actually happens (which we call error).
Conceptually, we can think of a person’s actual score on y (some variable) as the sum of our prediction and the error in our prediction (with the goal to minimize error as much as possible).
As an equation, we would write this as: actual.score = our.prediction + error
Great! But the real question is WHAT should define our prediction?
RECAP : The Mean (and Linear Model) as Prediction
Previously, we learned how the mean was a simple way to make a prediction about individuals.
For example, if you wanted to know whether it would rain today, you might look at the average rainfall for today’s date, and use that average for your prediction.
Let’s review this idea, and set up the linear model, by working with a classic dataset in teaching statistics - the Prestige dataset. These data are contained in the car package, and are used in one of the classic R textbooks - John Fox’ Applied Regression Analysis and Generalized Linear Models (2nd Edition).
Code
# install.packages("car") # this installs a package - you only need to do this ONCE. Remove the # to run this code.library(car) # loading the library - make sure you installed it first!
Loading required package: carData
Code
presto <- Prestige # creating a copy of the dataset so you don't mess something up :)names(presto) # tadaa!!
You can read more about these variables by typing in ?Prestige to access the help page for the dataset. For this lecture, we’ll be working with the variable prestige, which is a measure of how prestigious certain jobs were, in Canada, in the 1960s1. Note that individuals in this dataset are not people, but people’s attitudes about types of jobs.
1 Super exciting! But remember this is like driving around a safe, boring parking lot!! We’ll hit the highway soon enough.
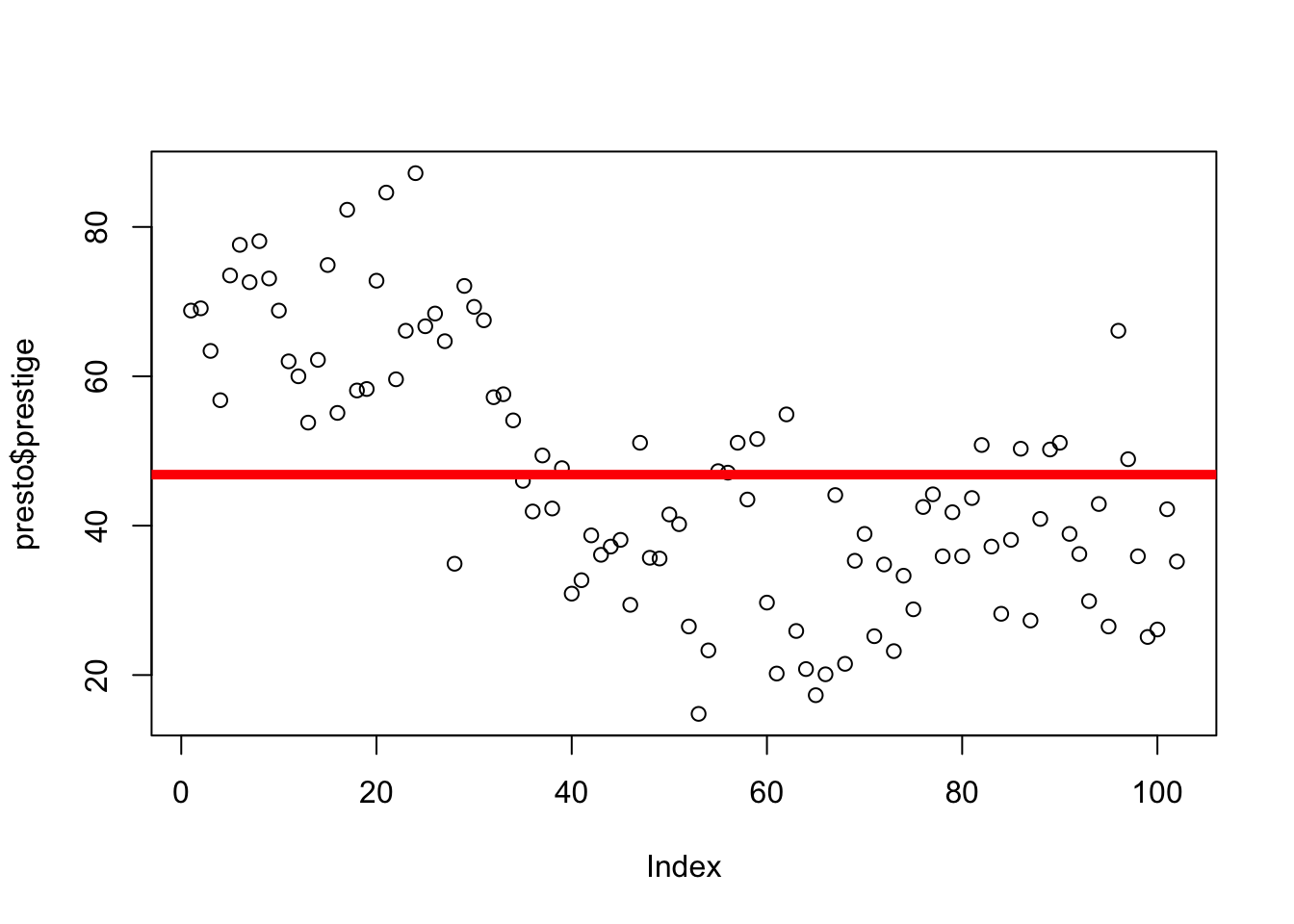
The graph to the right illustrates variation in this variable, as well as how the mean of prestige is the value that is closest to all the scores in the distribution.
The graph below 2 is defined by the following equation :
2 NOTE: Eagle eyed students may note something odd about the way the data are arranged on this graph - it looks like there’s some quadratic (curved) pattern in the way the data are arranged. Because the x-axis for this graph (the index) is the row in which each data, all this quadratic pattern means is that more prestigious jobs tended to be listed earlier in the dataset than less prestigious jobs.
Here’s a guide to what’s in the equation and on the graph!
\(\Large y_i\) = the DV = the individual’s actual score we are trying to predict (remember \(_i\) = index; a specific individual.)
on the graph: each individual dot (on the y-axis; the x-axis just describes when people submitted the survey.
\(\Large \hat{Y}\) = our prediction (the mean).
on the graph: the solid red line
\(\Large \epsilon\) = residual error = distance between the predicted values of y and the individual’s actual value of y
on the graph: the distance between each dot and the line.
The equation is fancy way of saying that an individual’s actual scores = our prediction (the mean) + error.
The mean was a good starting place to make predictions for two reasons :
By definition, the mean is the value that is closest to all the scores. In other words, the mean minimizes the error in our predictions.
The mean is static (it does not change), meaning we can make the same prediction for every person. This is a good place to start, but obviously there’s a lot of error in our predictions. In fact, using our knowledge of residual errors, we can calculate this total (squared) error when we use the mean to make a prediction.
This value is the total sum of the squared residuals (also called the sum of the squared errors or often abbreviated SST when focused on the residuals of the mean.
TLDR : we are interested in a variable (prestige), we can make pretty good predictions about prestige based on the mean (since by definition the mean is closest to all the scores in the data), and we are able to quantify how good our prediction is by calculating the sum of squared errors.
Next, we’ll try to improve upon our predictions of prestige.
The Linear Model : It’s Just a Line (With a Slope)
Basic Concept.
The linear model is a simple, yet flexible, way to make predictions about one variable (the DV or y). There are many types of models, but most follow the same basic principles that we will review in this document.
The mean is actually a linear model in its simplest form : y ~ 1 + error, with 1 serving as a constant value (the mean!).
The mean is a great starting place, but it’s limited because it’s static - we have the same prediction for everyone in the dataset, when we know that people differ. So we will want to come up with predictions that change, depending on what we learn about another person. This is something I refer to as the principle of covariation. It’s a simple idea - if there’s a pattern in how two things vary, then we can use information about one variable to make a prediction about what will happen for the other variable. This is what we talked about earlier in the semester when we discussed the idea of prediction - we’re just formalizing this idea with numbers now.
So, as a conceptual example, there is variation in rain (some days it rains and some days it does not) and there is variation in clouds (bright skies some days; clouds other days). The covariation happens as I notice that on days when it rains (variable = rain), it also tends to be cloudy (variable = clouds). These two variables vary together (they “co-vary”). Of course, this pattern isn’t always true - there’s error.
I could write this as a model, where my predictions about whether it will rain will be influenced by whether I see clouds in the sky : rain = clouds + error
I would use this model to make an adjustment to my prediction when it rains - if there are clouds, I might think it’s more likely that it will rain. That is, the presence of clouds changes my prediction. This change is a critical idea, and will be important to quanity - how large is the change? Does it improve my predictions?
As another example, think about how you would write an equation to model the idea that on days when it’s raining, I tend to hear raindrops (and on days when it’s not raining, I don’t tend to hear raindrops). I might write this model as rain = rain sounds + error
These two models look similar, but are not equal. If I had to guess, I’d say that hearing rain is a better way to make predictions of rain than looking at the clouds, meaning there would be less error in my predictions. So not only do models use information about which variables you can use to make predictions about another, but they also tell you how much you should update your predictions about one variable from another.
Prestige Example
Returning to our previous example, let’s predict the variable prestige from the variable education - another continuous variable in the Prestige dataset. As a linear model, I would write this as : prestige = education + error
In the same way I could expect rain sounds to be related to rain, a job that requires more years of education might be related to how prestigious the job is. This is not true of all careers (consider the “high educated” poet ridiculed by society, perhaps, or the “low educated” firefighter revered by society3.
3 And good to explore why we care about prestige in careers anyway? I blame capitalism and our society’s unwillingness to provide people with their basic needs, so a person’s value is determined by how much their material conditions, and whether they can meet (or exceed) those basic needs. Anyway, point is firefighters and poets are both cool and important for society.
Let’s graph these two variables side by side.
Code
par(mfrow =c(1,2)) # splits my graphing windowhist(presto$prestige, col ='black', bor ='white', main ="")hist(presto$education, col ='black', bor ='white', main ="")
Great. So both prestige and education vary. Not every job has the same prestige, and not every job requires the same years of education.
The question is whether these two variables covary. Are changes in prestige related to changes in education??
Pop Quiz: How can you see the relationship between prestige and education in the graphs above?
::: {.callout-tip collapse = “true”} You cannot!!! I’m guessing that some of you are thinking that because both distributions are slightly positively skewed, this means that there is some covariation between these variables. However, this is an example of patterns in randomness - we can’t really tell whether there is covariation from these two separate graphs. Instead, we need a different kind of graph that explicitly draws a connection between these two separate variables. This is the scatterplot, which you will learn about below :) :::
The Scatterplot
In order to examine how these two variables covary (that is, how variation in education is related to variation in prestige), we need to use a scatterplot.
A scatterplot graphs individual scores in terms of one variable on the Y axis (the vertical line) and the other variable on the X axis (the horizontal line).
To graph a scatterplot, you can use the plot() function, and tell R to predict one variable (in this case prestige) from another (education).
Take a look at the graph below - what do you see?
Code
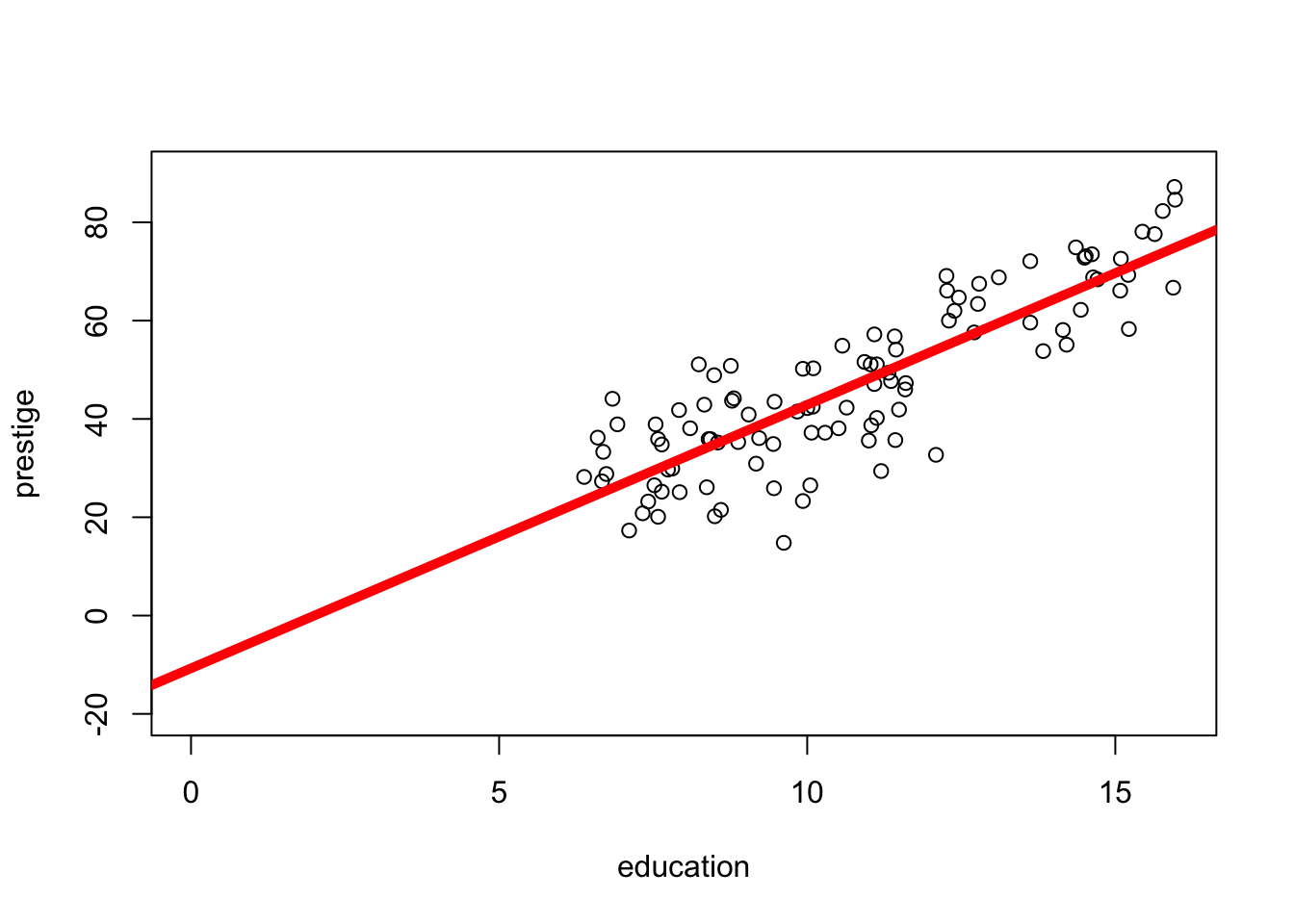
plot(prestige ~ education, data = presto)
Watch the video below for an explanation of what’s going on in the graph.
To define the model (as I did in the video), we just need to use a few lines of code.
Code
mod <-lm(prestige ~ education, data = presto) # this defines the model, and then saves it to an object (called mod)coef(mod) # this shows me the values of the model
(Intercept) education
-10.731982 5.360878
The linear model is just another line that updates our predictions of one variable based on knowledge of another.
This line (in red, on the graph below) has the following equation :
\(\huge y_i = a + b_1 * X_i + \epsilon_i\)
Code
plot(prestige ~ education, data = presto, # plots the model againxlim =c(0, 16), # changes my x-axis to range from 0 to 16ylim =c(-20,90)) # changes my y-axis to range from -15 to 90abline(mod, col ='red', lwd =5) # this adds the line to my graph.
\(\Large y_i\) = the DV = each individual’s actual score on the dependent variable.
on the graph: the value of each dot on the y-axis
\(\Large a\) = the intercept = the starting place for our prediction. You can think of the intercept as “the predicted value of y when all x values are zero”.)
on the graph : the value of the line at X = 0
\(\Large X_i\) = the IV = the individual’s actual score on the independent variable (a different variable than the DV).
on the graph : the value of each dot on the x-axis
\(\Large b_1\) = the slope = an adjustment we make in our prediction of y, based on the individual’s x value.
on the graph: how much the line increases in y value when x-values increase by 1 unit.
\(\Large \epsilon_i\) = residual error = the distance between our prediction and the individual’s actual y value.
on the graph: the distance between each individual data point and the line.
Test your understanding of linear models! Use the Prestige dataset and R to predict the variable income (the DV) from the variable education (the IV). You can try to do this in R on your own computer, or use the output below. Use this model to answer the questions for this check-in in the link above.
Call:
lm(formula = income ~ education, data = presto)
Coefficients:
(Intercept) education
-2853.6 898.8
Part 2 : Evaluating Error in Predictions
Remember our goal is to make good predictions that have little error. So to evaluate the quality of our predictions, we need to evaluate how much residual error there is - the distance between each point and the line.
Visualizing Residual Error in the Model
This is similar to what we did with the mean - we draw a line that is close to all the individual scores, and then calculate the sum of the squared errors. However, whereas the mean yields the same prediction for each individual (and the line is flat), the linear model yields a specific prediction for each individual’s y score, based on the value of x (and the line has a slope).
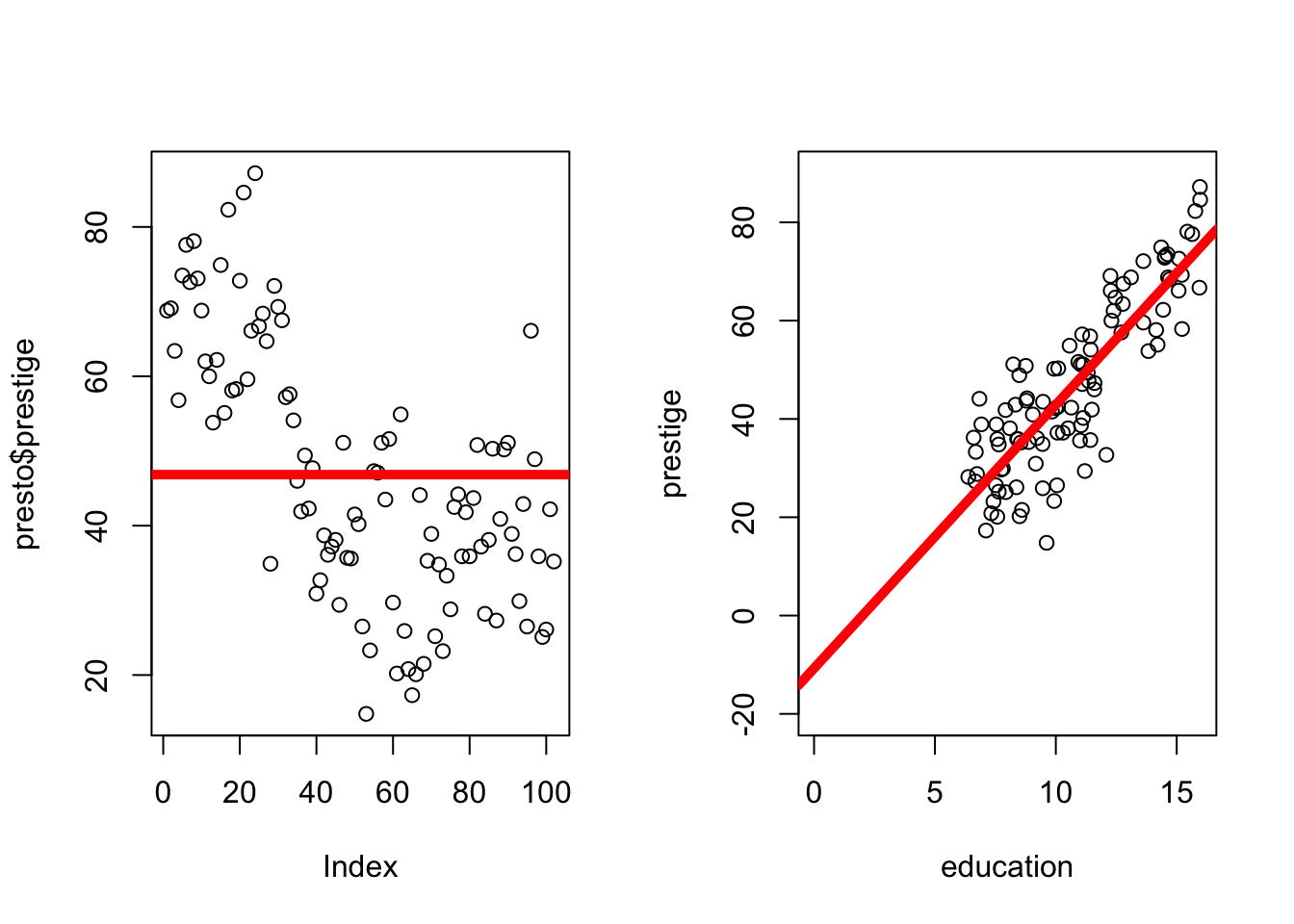
Below are two graphs - the one on the left uses the mean to make predictions of prestige, and the one on the right uses education to make predictions of prestige (our model).
Look at the two graphs - can you tell which one has more (or less) residual error?
Code
par(mfrow =c(1,2))plot(presto$prestige)abline(h =mean(presto$prestige), lwd =5, col ='red')plot(prestige ~ education, data = presto, # plots the model againxlim =c(0, 16), # changes my x-axis to range from 0 to 16ylim =c(-20,90)) # changes my y-axis to range from -15 to 90abline(mod, col ='red', lwd =5) # this adds the line to my graph.
Just by looking at two graphs, it’s clear that there’s less residual error when we use education to make predictions of prestige (vs. using the mean). In other words, the individual scores are further from the red line on the left graph than on the right graph.
Calculating Residual Error in the Model
Still, we are going to want to calculate these differences to describe just how much better our predictions are. What makes this potentially more challenging is that when we use a model to make predictions for individual scores, we will predict a different value for each individual based on the result of our model. For example, a job that requires 6 years of education will have a different predicted value of prestige than a job that requires 7 years of education.
Fortunately, R does the hard work of making predictions for us, and even saves the residual errors as part of the model output.
For example, from our model where we predicted prestige from education:
Code
head(mod$residuals) # these are the residuals (the errors from our model)
sum(mod$residuals^2) # these are the sum of the squared residuals when using the model to make predictions
[1] 8286.99
Notice that the sum of the squared errors for this model, where we use education to predict prestige, is less than the sum of the squared errors from the model where we used the mean to make predictions.
In fact, we can calculate exactly how large this difference in errors is between the two predictions.
Code
SSM <-sum(mod$residuals^2) # saving the sum of the squared errors from the modelSST <-sum(residual^2) # saving the sum of the squared errors from the meanSST - SSM # the difference in the squared errors from the mean vs. the model
[1] 21608.44
This tells me that the model where we use education to predict prestige reduces the squared error by 21608.44. That is a large number! But it’s hard to understand how large it is, because it’s missing context.
To provide this number context, we can describe how large this reduction in residual error is, relative to the original residual error that we had when we used the mean to make predictions.
Code
(SST - SSM)/SST
[1] 0.7228007
This number (.72) means that using education to predict prestige explains 72% of the total variation in prestige (when you use the mean to make predictions). If this sounds like a large percentage, you would be right - there’s no “rule” about what counts as a large or little percentage of variation explained.
This statistic is called \(R^2\) (“r-squared”), and is defined by the following equation.
What \(R^2\) does is contextualize our reduction in error, by describing how much less error we have in our model, compared to the error that we had when using just the mean to make predictions.
Another way to think of \(R^2\) is that it describes the percentage of variation in the DV that our model is able to predict or explain.
\(R^2\) can range from 0 to 1. The closer to zero, the less our model improves upon predictions (because 0 = no difference between the error when using the mean to make predictions and the error when using the model to make predictions). The closer to one, the more our model improves upon predictions. An \(R^2\) of 1 would mean that you are making perfect predictions. If this happens, you have probably done something wrong.
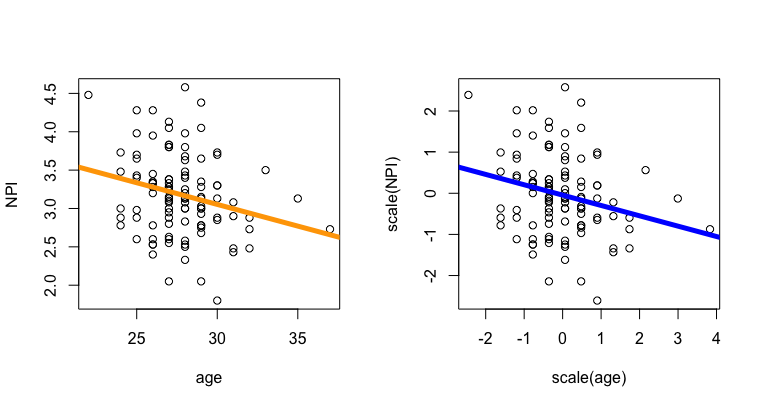
Video Example : Age and Narcissism
Remember our Narcissistic MBA students? They’re back, in Linear Model form!!!!
Here’s a super quick check-in on interpreting \(R^2\) values!
Part 3 : Interpreting Models with the Z-Score
WarningRECAP : Uhhh…can you re-explain Z-Scoring Professor???
A z-score describes how far an individual score falls above and below the mean (a residual!) in units of standard deviation. Z-scores are used to help give context to data - how far above or below the average is an individual (their distance from the mean), compared to the standard deviation (the average amount that people differ from the mean).
Z-scores can also be useful when the units of measurement don’t have any meaning. For example, let’s say you take a job on Jeff Bezo’s Mars ™ and learn that a job pays 1298723 BezosBucks. Is this a little? A lot? Well, knowing that it’s 120 BezosBucks above the average income might give you some indication that you are going to be better off than others on Jeff Bezos’ Mars ™. But how much better off?
If you learn the standard deviation of income on Jeff Bezos’ Mars ™ is 12, then your above average salary is 10 times more than what you’d expect the average person to differ from the average salary - you are gonna be VERY RICH compared to the average resident - drinking fresh water and breathing air created by the finest asteroidoxygenators!
But if the standard deviation is 1200, then your z-score = .1, which means you are only a tenth of a standard deviation above average, which means that you will be lumped with the masses on Jeff Bezos’ Mars - slurping recycled air with the rest of us.
Why Z-Score in a Model
In a linear model, the slope describes the relationship between the two variables in whatever units the DV and the IV were measured in. So in our prestige example, the slope of 5.36 means that for every 1-unit increase in years of education, our prediction of prestige goes up by 5.36 points. Is that a little change in prestige? A lot? It’s hard to know, since prestige is not tangible, but a human-created construct.
Which brings us back to z-scores. If we z-score both the DV and the IV in our linear model, the (arbitrary) units of measurement disappear, and both variables are described in terms of standard deviation. This allows us to better relate each variable to another. To z-score the variables in a model, you just use the scale() function inside the linear model.
Click the tabs to switch between Raw Units and Z-Scored Units. What changes? What stays the same??
Here’s the graph, in the original units of measurement.
Code
plot(prestige ~ education, data = presto, ylab ="Prestige (Raw Units)",xlab ="Education (Years)") mod <-lm(prestige ~ education, data = presto)abline(mod, lwd =5, col ='red')
And here’s the result of the model.
Code
round(coef(mod), 2)
(Intercept) education
-10.73 5.36
Here’s the graph when the DV and IV are Z-Scored.
Code
plot(scale(prestige) ~scale(education), data = presto, ylab ="Prestige (Units of Standard Deviation)",xlab ="Education (Units of Standard Deviation)") zmod <-lm(scale(prestige) ~scale(education), data = presto)abline(zmod, lwd =5, col ='red')
And here’s the result of the model.
Code
round(coef(zmod), 2)
(Intercept) scale(education)
0.00 0.85
Interpretation of Z-Scores
As before, the data do not change - the only thing that changes are the units in which the DV and IV are measured (and thus the units of the intercept and slope).
The intercept of a z-scored model will always be zero (or something very near zero). Remember that a z-score of zero means average, and the intercept is defined as “the predicted value of the DV when all IVs are zero.” This means that….
…the predicted value of the DV is zero when the IV is zero.
…someone with the average IV (IV = z-score of zero) is predicted to have the average DV (DV = z-score of zero), or
The slope of a z-scored model describes the relationship between the variables in units of standard deviation. When both the DV and IV share the same units of measurement, the slope becomes a lot more informative, since it tells you exactly how linked the two variables are. Knowing that for every 1-unit increase in years of education, the predicted prestige goes up by 5.36 (the slope) makes far less sense to me than knowing that for every standard deviation increase in years of education, the predicted prestige goes up by .85.
The maximum slope of a z-scored linear model (with one IV) is 1 (one). This would be a perfect positive relationship, where a one standard deviation increase in the IV is equal to a one standard deviation increase in the DV.
The minimum slope of a z-scored linear model (with one IV) is -1 (negative one). This would be a perfect negative relationship, where a one standard deviation increase in the IV is equal to a one standard deviation decrease in the DV.
A slope of zero would mean that there’s no relationship between the two variables.
Wait a minute…that’s….CORRELATION COEFFICIENT’S MUSIC.
Yes, class, a correlation - the relationship between two variables, is just the standardized (z-scored) slope of a linear model (with one IV).
Code
cor(presto$prestige, presto$education) # the correlation
[1] 0.8501769
Code
coef(zmod)[2] # the slope of our z-scored model
scale(education)
0.8501769
Wow! We will chat more about this in the video below, and in lecture next week :) thanks for reading!
Video Example : Age and Narcissism (Z-Scored)
The video above walks through z-scoring in another example, from the narcissism dataset.